Transitive relations, a deeper dive.
∀a,b,c∈X: (aRb ∧ bRc) ⇒ aRc. If a R related to b and b R related to c then a R related to c.
This is the definition of transitive. What's interesting is what it doesn't say, it doesn't preclude cycles, i.e. aRb ∧ bRc ∧ cRa. There are two ways transitive relations can be found, either through search or via some matrix math. Prolog is implicitly a depth-first search, when we backtrack we continue from the most recent choice point, which results in depth-first search. So we'll focus on that.
Simple case: no cycles
If you can guarantee that your domain is a tree structure without cycles, then you can use the typical definition found in beginners books and in Reflexive, Symmetric and Transitive Relations in Prolog.
connected(A, B) :- edge(A, B).
connected(A, B) :- edge(A, C), connected(C, B).
But if you've got a cycle, this will get lost in an infinite loop.
Dealing with cycles
The typical way to manage cycles in depth-first search is to maintain an extended list, which contains the nodes already extended (traversed/ searched/ visited). This is then used to ensure that these nodes are not revisited, which is also useful in a highly connected domain as it reduces the search space.
We'll use an example with a graph:
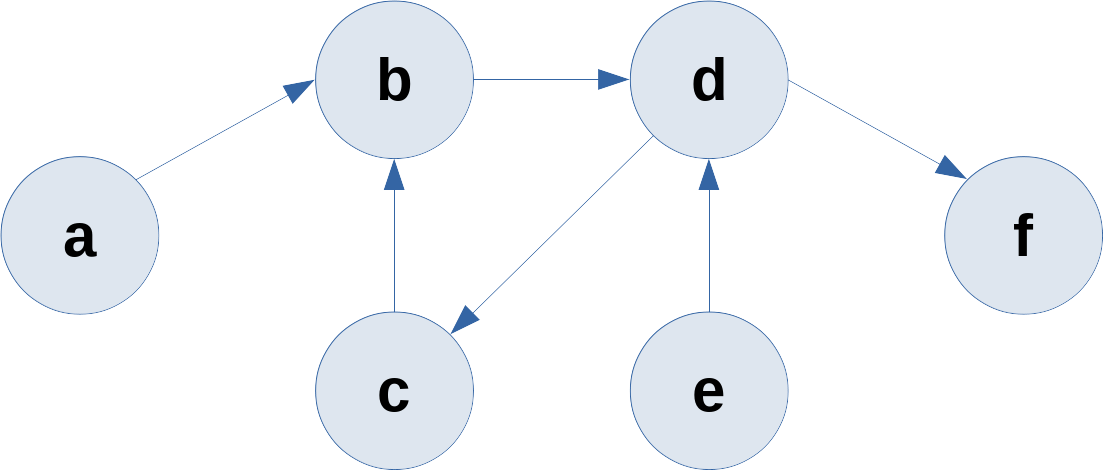
Or in code:
:- use_module(library(lists)).
edge(a, b).
edge(b, d).
edge(c, b).
edge(d, c).
edge(e, d).
edge(d, f).
% setup extended list
connected(A, B) :-
% we've already visited the origin
connected(A, B, [A]).
% A is connected to B if there's an edge
% but fail if we've already extended B
connected(A, B, ExtendedList) :-
edge(A, B), \+ member(B, ExtendedList).
% Transitive case, find a node that's
% connected by and edge and not extended
% and carry on from there
connected(A, B, ExtendedList) :-
edge(A, C), \+ member(C, ExtendedList),
connected(C, B, [C|ExtendedList]).connected(a, Node).You should find that a is connected to b, d, c, and f. Not only that, but we didn't get lost in the b→d→c→b cycle. This program is worth running on your own machine so you can trace it and see how that extended list works.
Optimizations
Depending on your Prolog implementation and particular domain, there are a few optimizations to consider. Some dialects offer a memberchk/2 predicate that is a little more efficient for this use case. If your domain is highly connected and you're doing very many membership tests, you might want to use an ordered set instead of a plain list, some dialects offer predicates such as ord_memberchk/2, ord_add_element/3 or ord_intersection/4 . The last on is useful if you'd like to get all of the child nodes at once as done by Richard O'Keefe's implementation in "The Craft of Prolog".
Finally, if you're in one of the rare Prolog dialects that support tabling, you can dispense with the extended list entirely and just table the predicate. This won't get stuck in cycles and it will reduce repeated search times significantly. But before you let the magic of tabling solve the problem for you, take the time to learn a little about search algorithms and how they work. After all, search is fundamental to how Prolog works.
Further Resources
The aforementioned "The Craft of Prolog" is excellent reading on search using Prolog, including breadth-first search and using heuristic measures of distance. Also, we highly recommended the freely available MIT AI lecture series given by Prof Patrick Henry Winston, which over lectures 4 and 5 goes from Depth-First Search to A*.